前言及預期效益
動機:樣態多元且大量的智慧文檔、發票等資料格式,人工處理成本高。本專案開發AI光學辨識系統,提高效率並解決問題。
目標:基於PaddleOCR與SuryaOCR技術,建立高效能的OCR系統,可進行智慧檔區塊切割、辨識與歸檔,並透過半自動標註模式提升辨識精度。
預期效益:系統適用多種場景,支援錯誤修正與回饋,並能隨資料累積重訓練模型,提升準確度與泛化能力。
研究方法及步驟
系統架構:前端使用React.js,後端使用Flask,資料庫採用MySQL。包含OCR影像辨識功能與表格擷取功能。
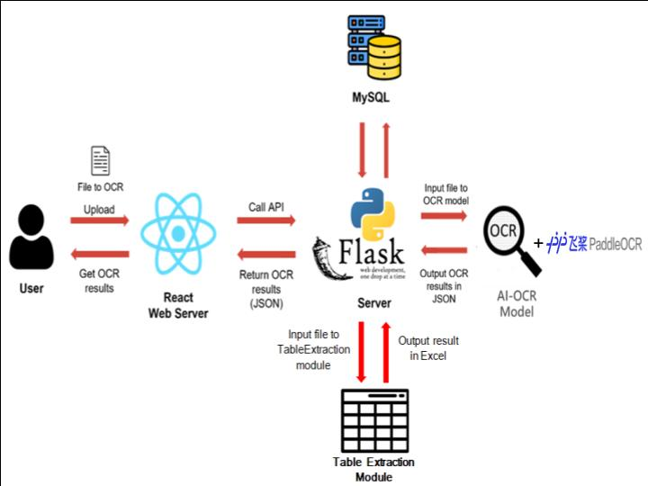
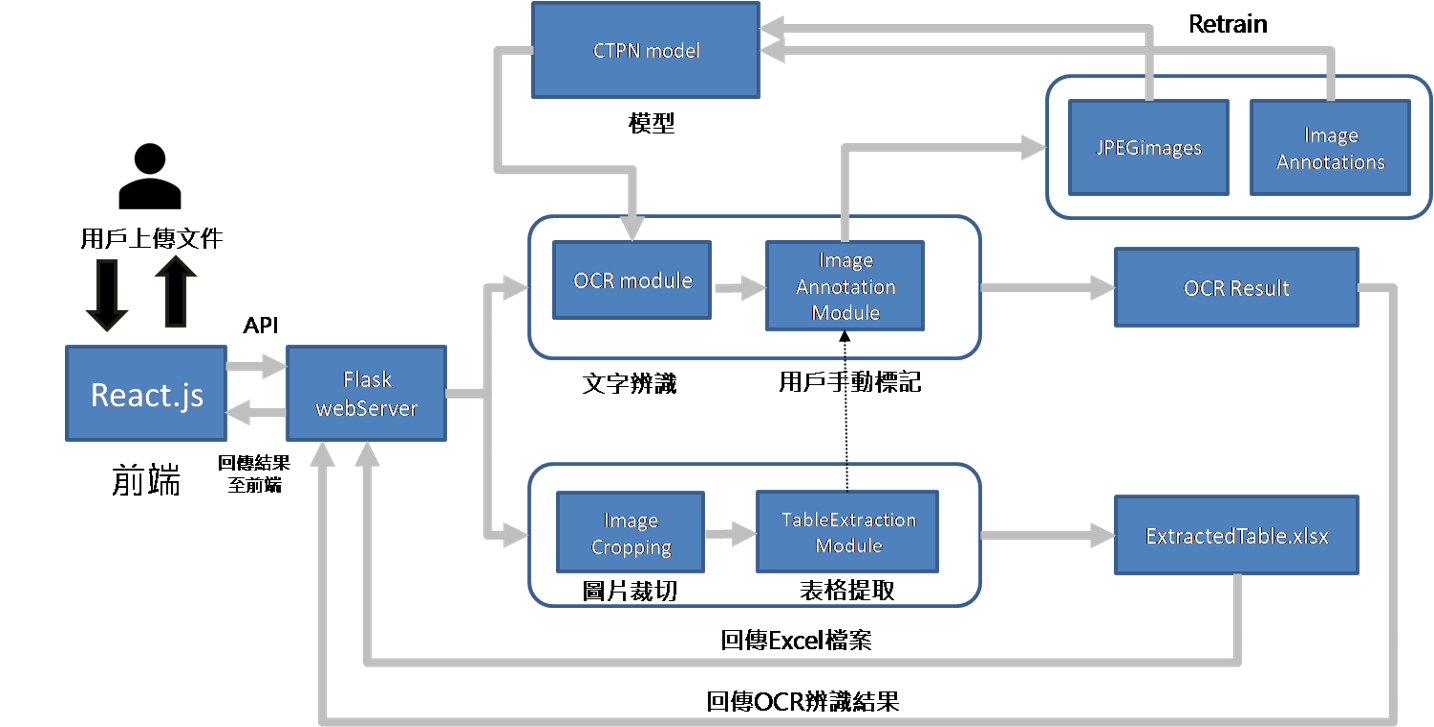
流程圖:圖片上傳至後端,經模型處理後以JSON格式回傳結果,支援手動修正與回饋。
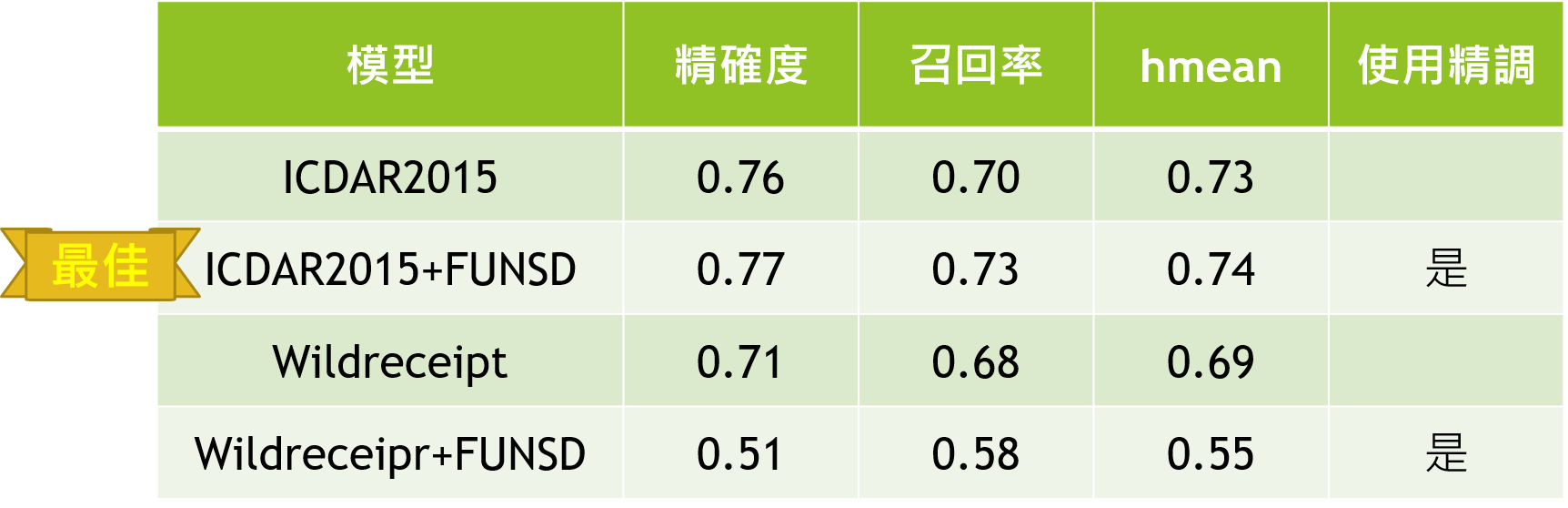
使用多種資料集進行訓練與測試,包括ICDAR2015、FUNSD、WildReceipt,模型效果穩定提升。
執行成果與討論
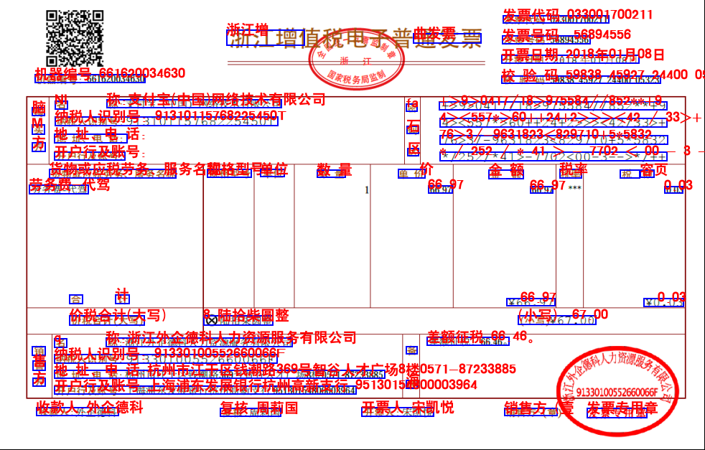
表格擷取畫面展示。
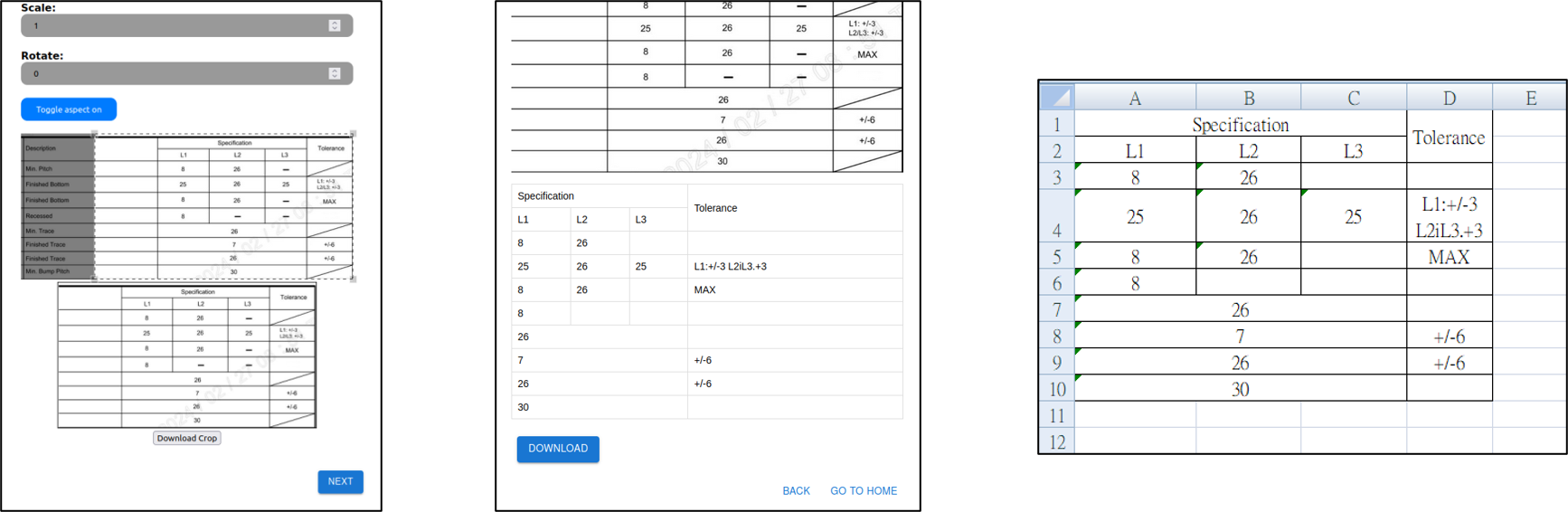
光學文字辨識畫面展示


結語
本系統有效結合AI與深度學習技術,解決智慧檔案處理效率問題,提供高度適用的解決方案,未來應用場景廣泛,為數位化轉型提供有力支持。
心得感想
我的專題是產學合作,所以嚴格意義上比較像是實習,公司會提出想要的大方向,然後我們提供解決方案,在參與專案的開發過程中,我深刻體會到人工智慧技術對於現實問題解決的巨大潛力與挑戰。本專案旨在解決智慧檔案的處理效率問題,從技術選型到實際實現,我在每個階段都學到了寶貴的經驗。在實現過程中,我們選用了 PaddleOCR 和 SuryaOCR 作為核心技術。從模型選擇到資料集訓練,每一步都面臨不少挑戰,例如如何處理不同格式的資料、如何優化模型的辨識準確度,以及如何設計靈活的系統架構來滿足多樣化需求。透過團隊合作和不斷實驗,我不僅加深了對深度學習和OCR技術的理解,也學會如何針對實際應用需求做出技術決策。系統的架構設計讓我更加熟悉前後端整合,包括使用 React.js 建置前端互動頁面,以及利用 Flask 實現後端 API 的高效處理。在處理資料庫與JSON格式傳輸時,我也學習到了如何確保數據的結構化與一致性,並設計了用戶友好的界面與交互流程。